


本次的课程主要包括三大部分:
1. Flink基本原理概述。指导学员了解并掌握Flink使用过程中设计到的基本概念和简要API,介绍大数据实时流计算相关生态体系,着重梳理清楚Flink上下游体系,掌握Flink的核心技术原理,建立大数据实时流计算的方法论思维。

2. Flink实战生产技术。从实战出发,围绕实时流计算业务场景分析、基本编程模型、高级特性等系统性介绍Flink实时流计算的实战技术,使得学员具备研发Flink实时流计算相关应用的基础能力。
3. Druid是一款支持数据实时写入、低延时、高性能的OLAP引擎,具有优秀的数据聚合能力与实时查询能力。在大数据分析、实时计算、监控等领域都有特定的应用场景,是大数据基础架构建设中重要的一环。本次课程我们将介绍Druid的核心特性与原理,以及在性能调优以及最佳实践经验。
资源目录:
第一课: Flink基本概念与部署
1. Flink 简介
2. 编程模型
3. 运行时概念
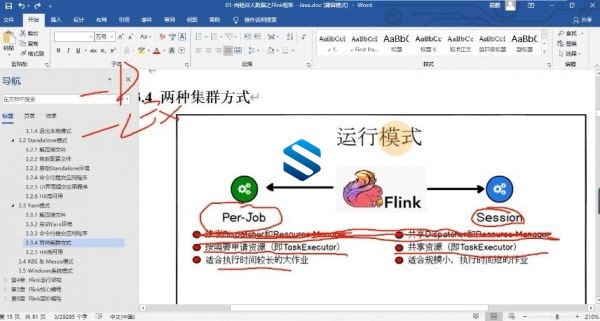
4. 应用部署与原理
a. 部署模式
b. On-Yarn 启动设置与原理
c. Job 启动设置与原理
第二课: DataStream
1. DataStreamContext环境
2. 数据源(DataSource)
3. 转化(Transformation)
4. 数据Sink
第三课:Window & Time
1. Window介绍
a. 为什么要有Window
b. Window类型
2. Window API的使用
a. Window的三大组件
b. Time&watermark
c. 时间语义
d. 乱序问题解决WaterMark
e. AllowLateness正确设置与理解
f. Sideoutput在Window中的使用
3. Window的内部实现原理
a. Window的处理流程
b. Window中的状态存储
4. 生产环境中的Window使用遇到的一些问题
第四课: Connector
1. 基本Connnector
2. 自定义Source 与 Sink
3. Kafka-connecotor
a. Kafka 简介
b. Kafka Consumer 与Sink 的正确使用方式
c. Kafka-Connector 内部机制与实现原理
第五课: 状态管理与恢复机制
1. 基本概念
2. KeyState 基本类型及用法
a. ValueState
b. ListState
c. ReduceState
d. FoldState
e. AggregatingState
3. OperatorState基本用法
4. Checkpoint
a. 概念
b. 开启checkpoint
c. 基本原理
第六课: Metrics 与监控
1. Metrics的种类
2. Metrics的获取方式
a. Web Ui
b. Rest API
c. MetricReporter
3. 用户自定义Metric指标方式
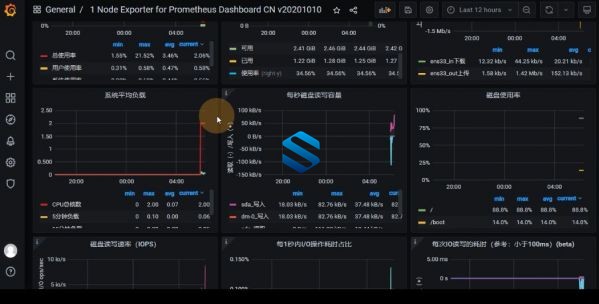
4. 监控和诊断:Metric和Druid 实时OLAP联合使用
a. Metric上报
b. Metric指标聚合
c. Metric的分类和格式定义
5. Druid查询和指标系统
a. Flink作业反压监控
b. Flink作业的延迟监控
c. 其他
6. Metric系统的内部实现
7. 生产环境中的案例分析 — 通过指标来排查应用问题
第七课: Flink应用案例介绍
1. 数据清洗:map/flatmap等
2. 监控告警系统
a. 数据拉平
b. 基础窗口计算等
3. 线上运营系统
4. 风控系统
第八课: Druid基本概念与架构设计
1. Druid与OLAP VS Kylin、ES等
2. Druid与指标系统 VS 各种时序数据库
3. Druid特性
4. 基本架构:角色节点与基本职责
a. 角色行为
b. 角色暴露的API
5. 基本架构:外部依赖
a. MySQL数据结构
b. ZK数据结构
c. HDFS数据结构
第九课: Druid数据写入与查询
1. 数据流向与存储格式
a. 数据写入流程
b. 存储与索引格式
2. 实时数据写入
a. Firehose
b. Realtime Node
c. Index-Service原理介绍
d. Tranquility原理介绍
e. Kafka-index-service原理
3. 离线数据写入
a. Indexer
b. MR Indexer
4. 查询模式与查询类型介绍
第十课: Druid实践介绍
1. 容错设计
2. 指标监控
a. 基于Graphite搭建指标监控系统
b. 重要的指标项
3. 运维实践
a. 数据修复
b. 集群升级实践
c. Segment元数据管理
d. JVM调优
c. 资源隔离






还没有评论,来说两句吧...